In my typical stream of consciousness format, here are some guidelines that can be used to help create a multi-tenancy environment that helps scale VPN Connections, but that considers different security scenarios per the given network connection back to on-premise.
Basic – What is static Routing? – Manually defining Subnet Ranges which should than refer to the next hop.
Basic – What is Dynamic Routing? – Routes are added automatically when the routes are advertised over BGP to its route table.
Basic – What is a blast Radius? – it is the concept of not putting all your eggs in one basket in the sense that if there is a vulnerability in an instance, it could potentially connect to all other network infrastructure in which are equally vulnerable.
What is BGP Advertisement? – no answer could give this justice
Basic – What is the difference between Regional Advertisement in GCP? – it advertises primary and secondary routes to all Cloud Routers in the VPC in the Same Region. The implication is that if your Cloud VPN is connected to this region, it can only propogate routes to the On-prem network from the VPC’s in this region. Peered VPC’s in the same region will be able to access the vpn, but not Peered VPC in different regions. Why use this: Mainly / Simplicity of connecting infrastrure in 1 region. for GDPR Reasons Only
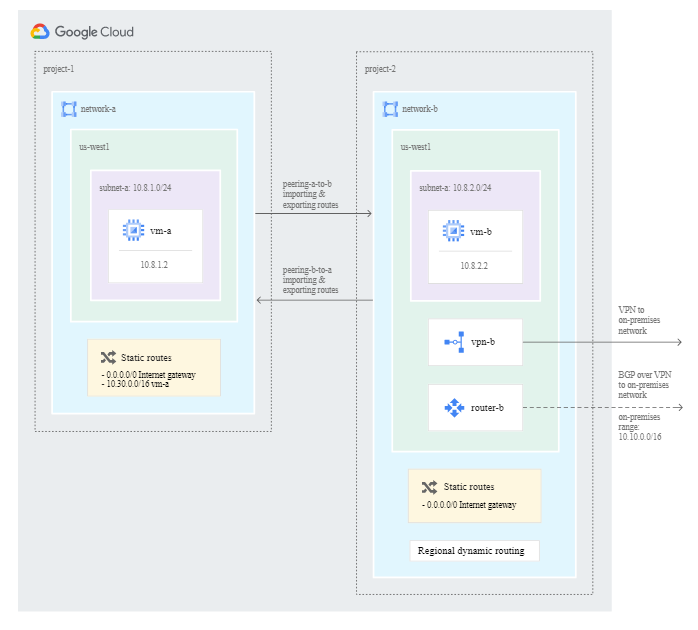
Basic – What is the difference between Global Advertisements in GCP? – it advertises the primary and secondary routes to all regions that are a part of the same vpc. The implication is that if your Cloud VPN is connect to one of the regions in which the VPC has a subnet, it should allow for multi-region advertisements of that VPC across multiple regions. Any VPC / Peered / Shared VPC in any region should be able to access the VPN. Why us this: Flexibility / Low Security Infrastructure.
Question – If Network A ( That hosts the VPN Connection ) is peered with Network B – Can Network B Access the VPN Connection Behind Network A? – Yes according to this documentation: https://cloud.google.com/vpc/docs/vpc-peering#transit-network
Recipe – Only Advertise Certain GCP Subnets over BGP to your On-prem Customer Gateway ( TBD )
Recipe – How to connect Multiple Service Project VPC’s to a host VPC Project that maintains the VPN Connection – All the subnet’s that you separate in your VPC(S) should be encompassed within the advertised Subnet Block that corresponds to the subnet block of your vpn. The main host VPC should have more than enough IP’s for shared infrastructure like DC’s and Such.
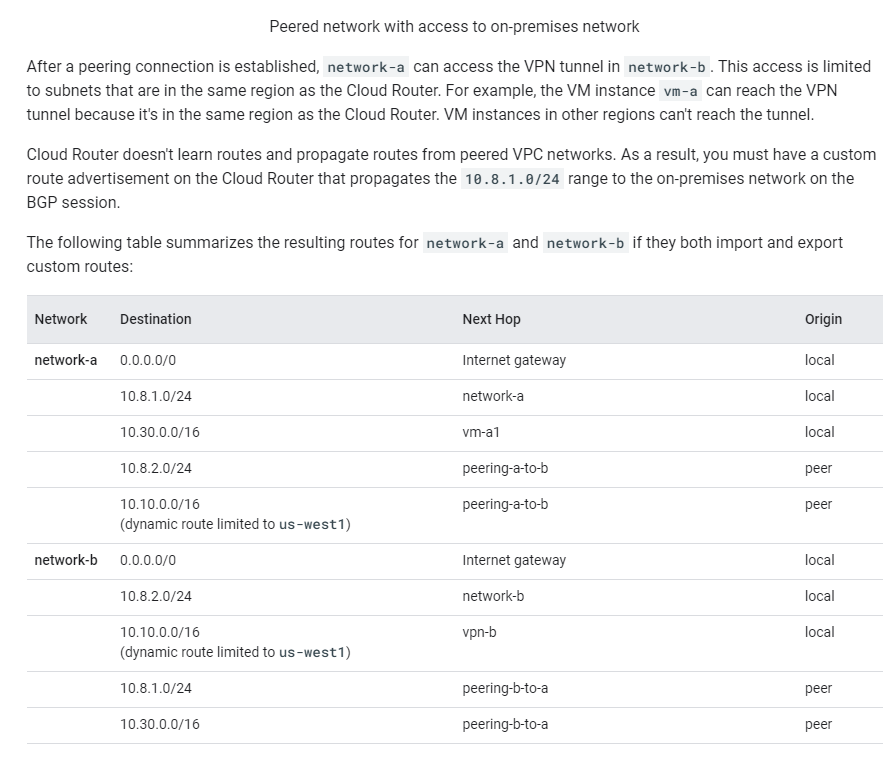
Peered VPC(s) should be inside the VPN’s subnet block and ideally not located too far away from the intended VPN in order to minimize latency. As the Cloud router does not learn routes between the peered VPC’s, the VPC Networks and setup a custom route advertisement on the cloud router to advertise the Subnet.
if GDPR / Hosting Data protection is needed, us Regional routing and only Peer with regions in that satisfy the compliance requirements. Regional routing may be best practice in order to fruther limit the blast radius of any given infrastructure, but it will require more VPN connections.
It is not recommended to host any infrastructure within the host / shared VPC.
notes – https://cloud.google.com/vpc/docs/vpc-peering#transit-network

How wide should Global Advertisement Apply in GCP for a VPC? – Although it would not be recommended to span a VPC in every region for latency reasons, it should at least be connected to all the regions in that particular continent related to that vpn connection. EX. if your VPN Connections is in California and New York, you could conceivably span across all regions on the east coast for the New York VPN Connection and another VPN connection to cover all the West Coast Regions. Place primary Infrastructure in the same region as the vpn, place DR / Seconary infrastructure on non-main infrastructure regions.
Simple chart to show which configuration should allow for certain VPN Access Configurations

What is the main benefit of using firewall rules with tags in GCP? – better flexiblity to utilize common firewall rules without defining another security group ( like in AWS ) to encompass all your other more common rules. Give your Firewall rules an alias like “ssh-internal” to represent both protocol and direction.